Abstract
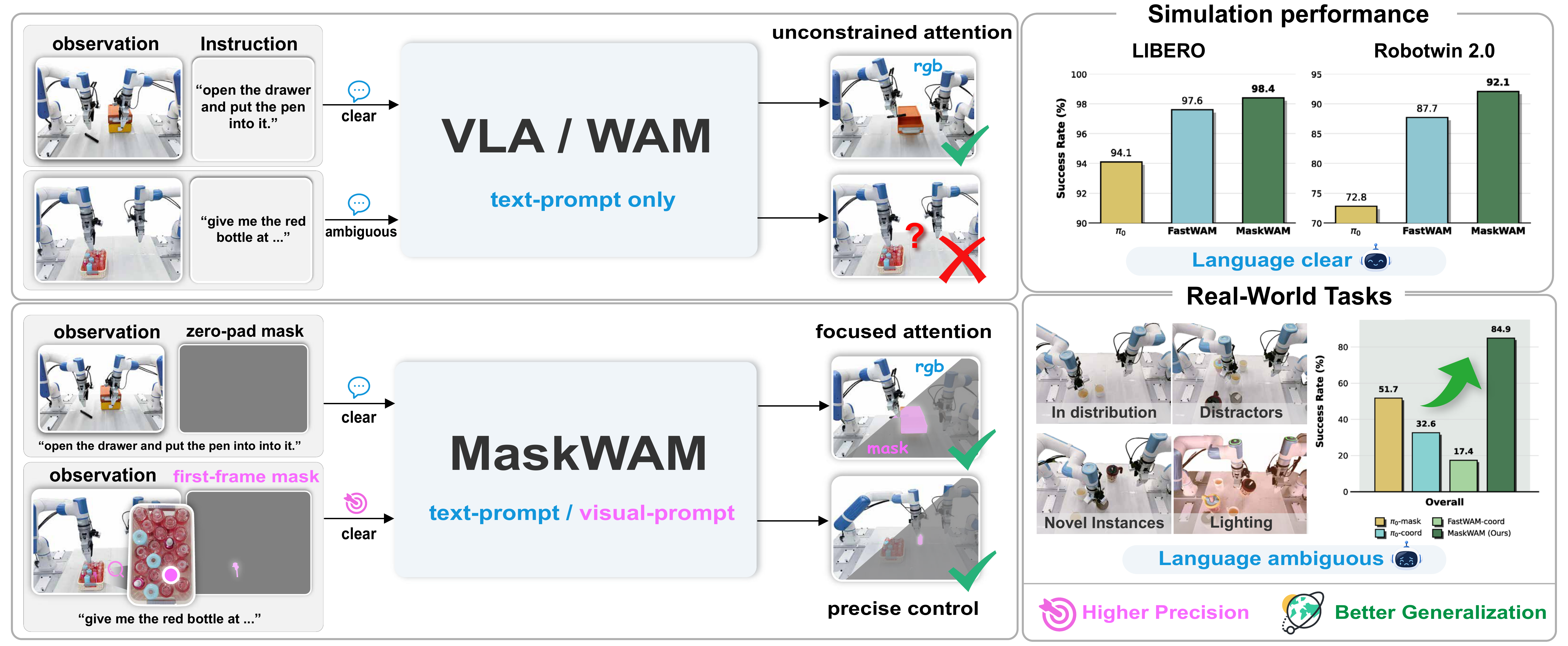
World Action Models (WAMs) present a promising paradigm for robotic control via video prediction. However, current WAMs suffer from fundamental spatial bottlenecks: standard text inputs introduce referential ambiguity in cluttered scenes, while unstructured RGB predictions lack semantic grounding and remain biased by task-irrelevant backgrounds.
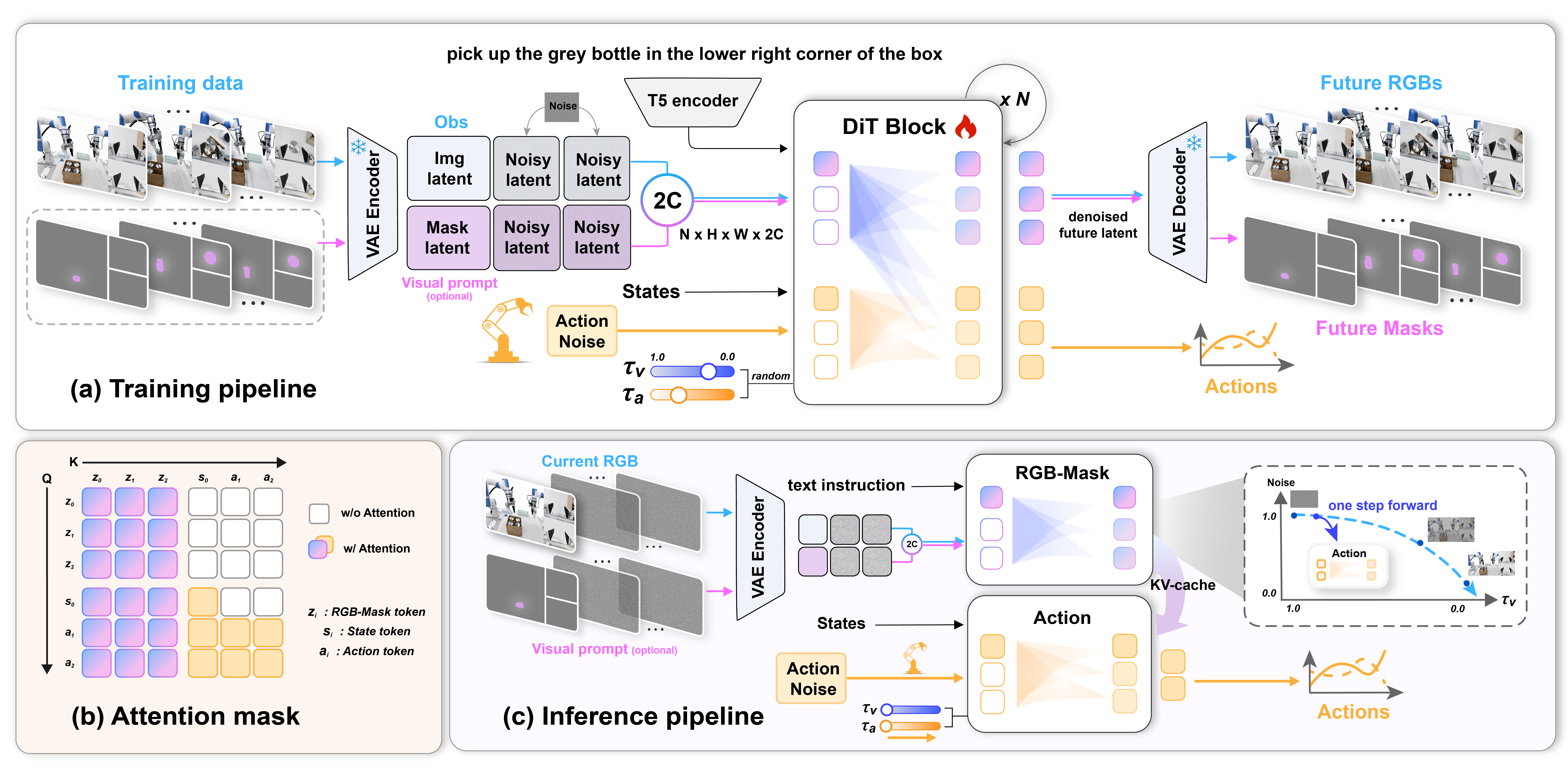
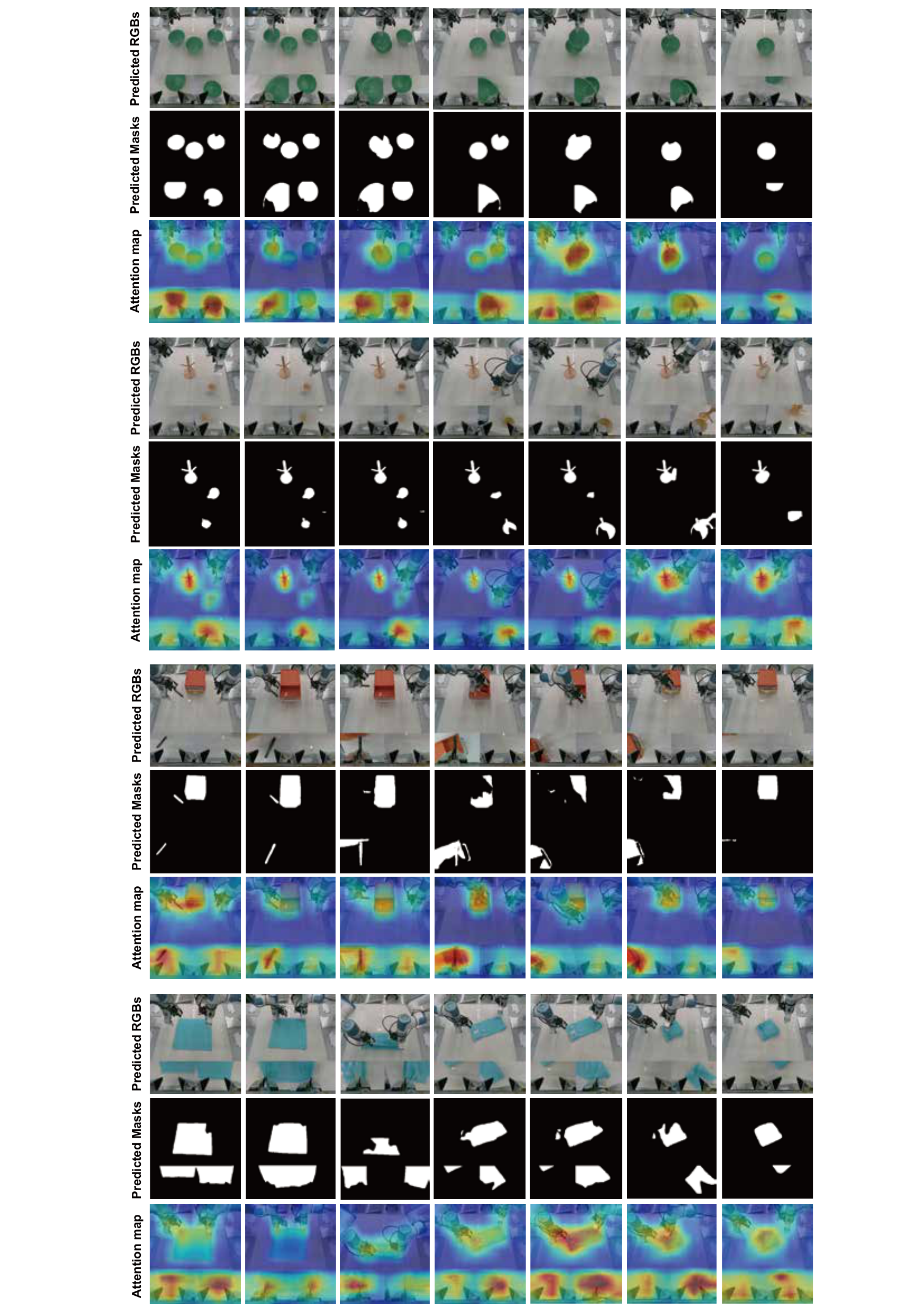
To overcome these limitations, we introduce MaskWAM, an object-centric world-action model. By jointly integrating masks as both explicit inputs and predictions via a unified Mixture of Transformers (MoT), MaskWAM unlocks robust policy generalization. This design provides two key benefits: (1) predicting future masks yields object-centric semantic supervision that suppresses visual noise, significantly enhancing even standard text-conditioned WAMs; and (2) coupling this predictive supervision with first-frame visual prompts, such as target object masks, establishes a precise spatial anchor that substantially reduces language ambiguity.
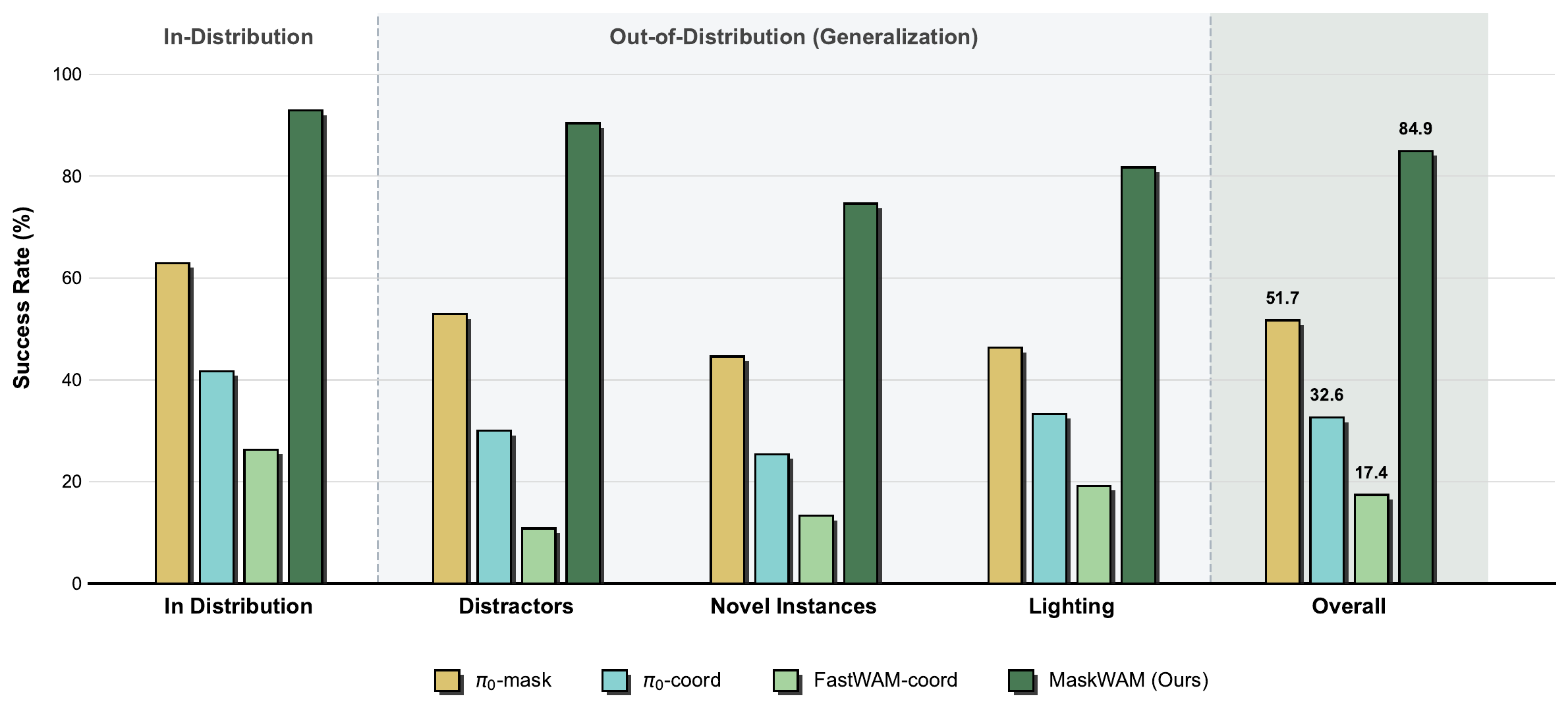
Crucially, as WAMs are inherently vision-driven architectures, direct mask conditioning yields substantially stronger guidance than text alone, establishing a precise and robust paradigm for manipulating unseen objects. Evaluations on LIBERO, RoboTwin, and real-world tasks demonstrate that MaskWAM significantly outperforms baselines in both language-clear and language-ambiguous tasks.